Amazon S3 is a great way to host files. It is similar to Google Drive, Apple iCloud, and Microsoft OneDrive, but for developers. Files are uploaded into Buckets under specific Keys. They can then be downloaded from around the world. There is a little bit more to it, but that is the main gist.
Each new upload brings a risk. A new file or a new version of an existing file could be incompatible with its consumers. Depending on the coupling, this could cause outages.
Versioning is a great way to mitigate this.
Amazon S3 versioning
Amazon S3 has a built-in versioning solution. It can be enabled in the bucket’s properties tab.
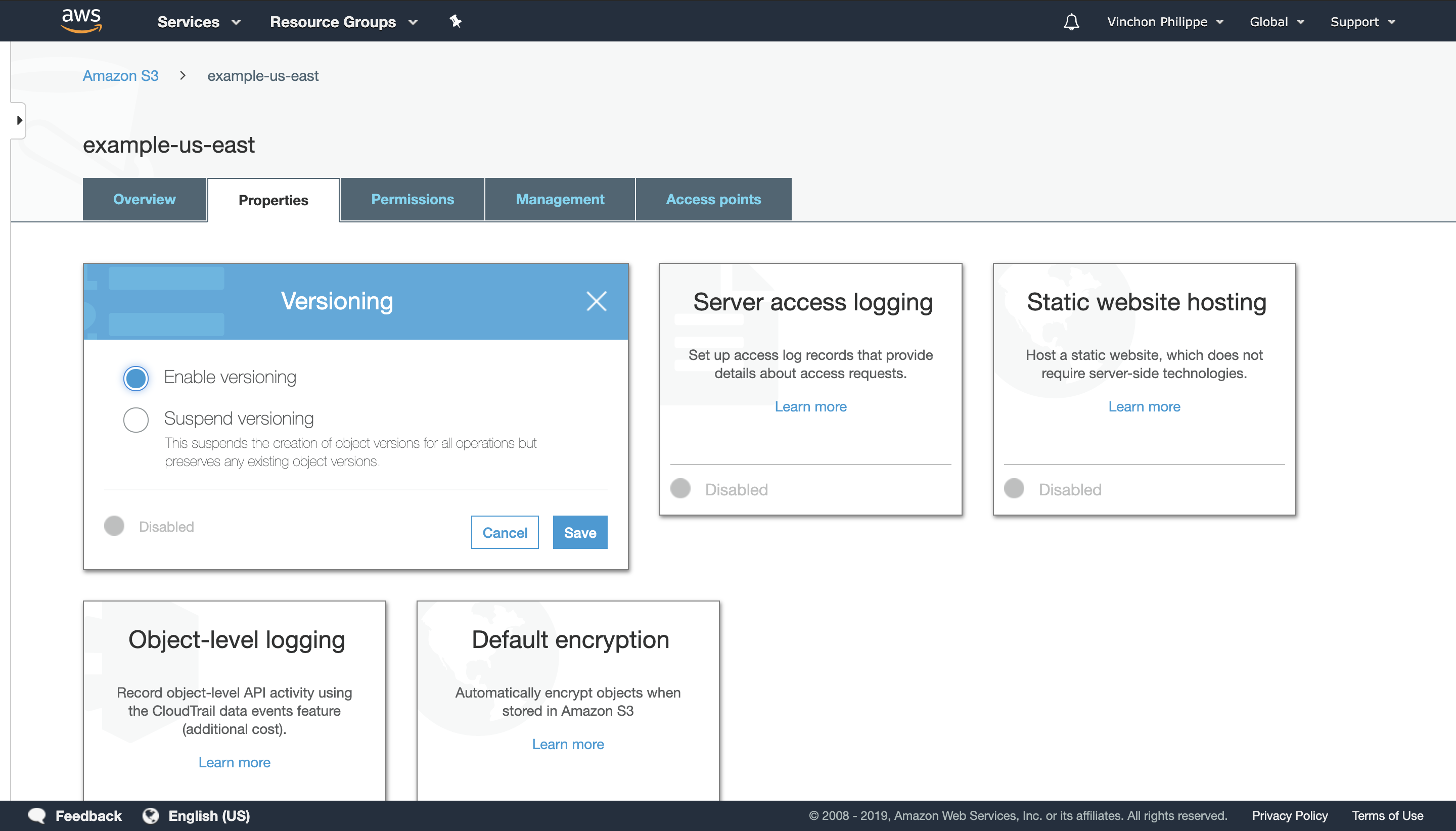
Once enabled, objects are never overwritten. Uploading multiple files to the same Bucket and Key will create new versions. Amazon S3 will return the latest one if none is explicitly requested.
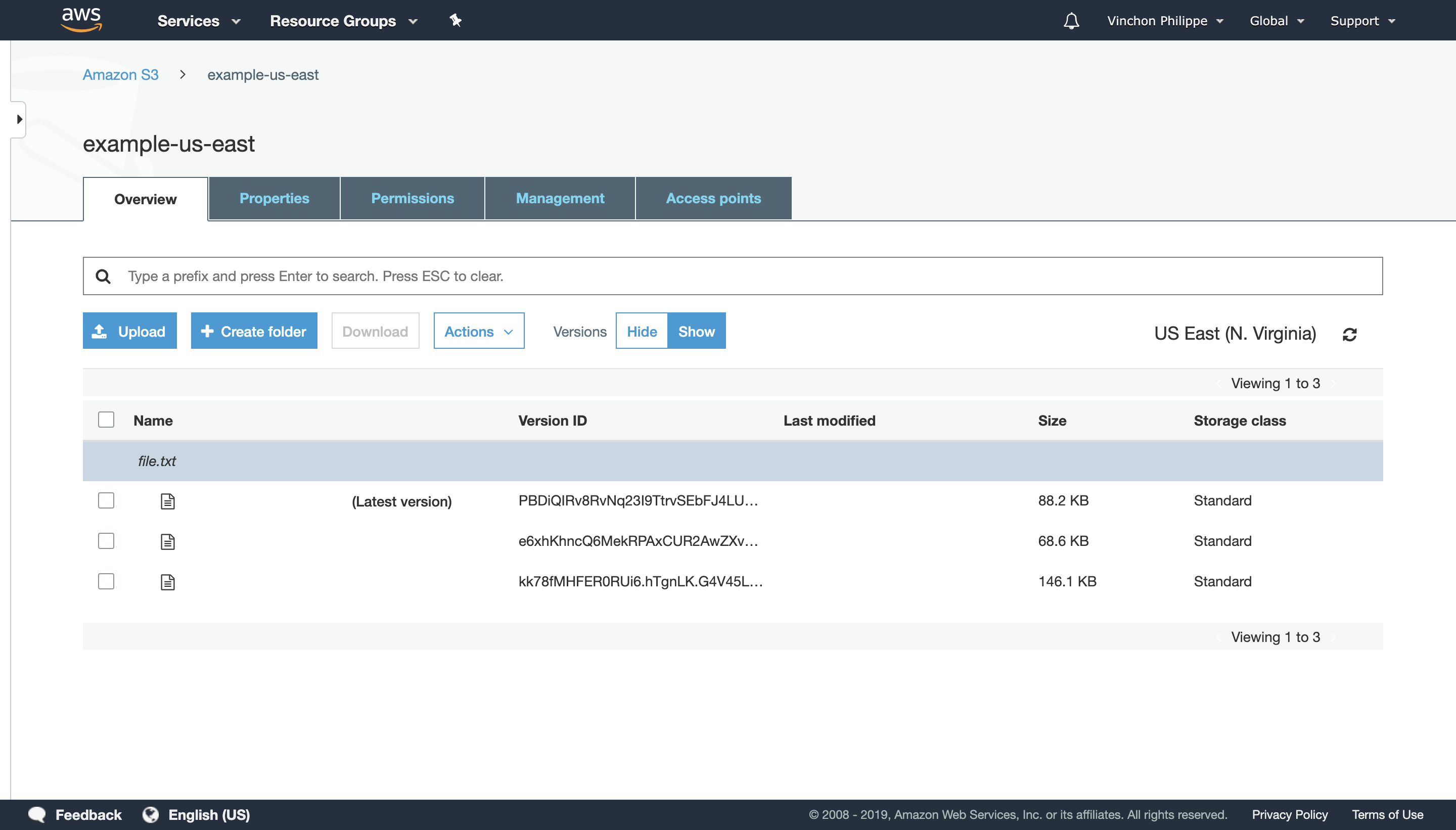
Furthermore, objects are never deleted. When an attempt is made, a new version is added to the Bucket and Key pair. That version is flagged to be unavailable.
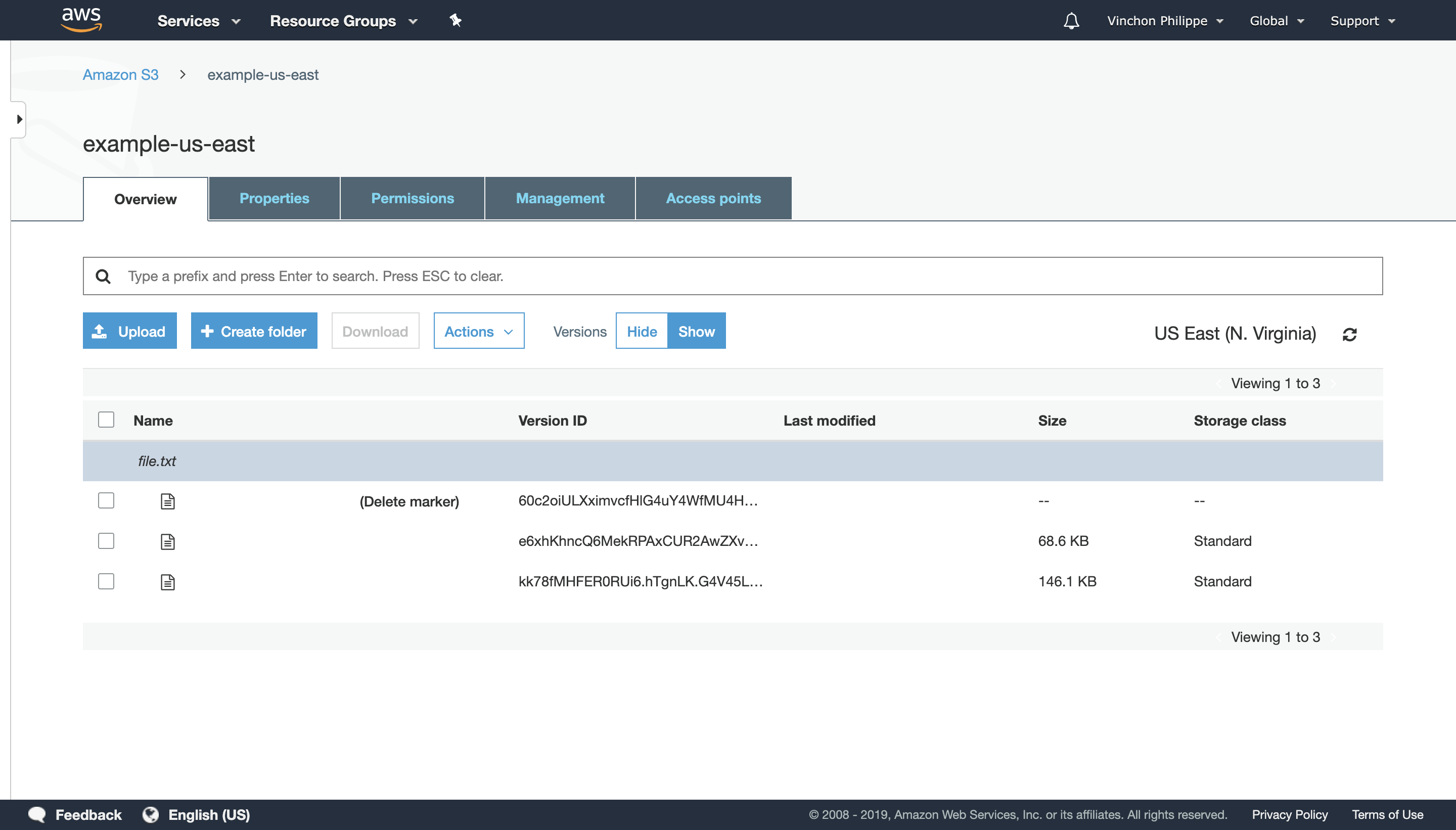
While objects can’t be deleted, versions can. This offers a revert mechanism.
Reverting changes
If an outage is related to an Amazon S3 file it can be quicker to revert to a previous version instead of generating a new one.
Selecting the bad version and deleting it can be done in 5 clicks on the AWS Console.
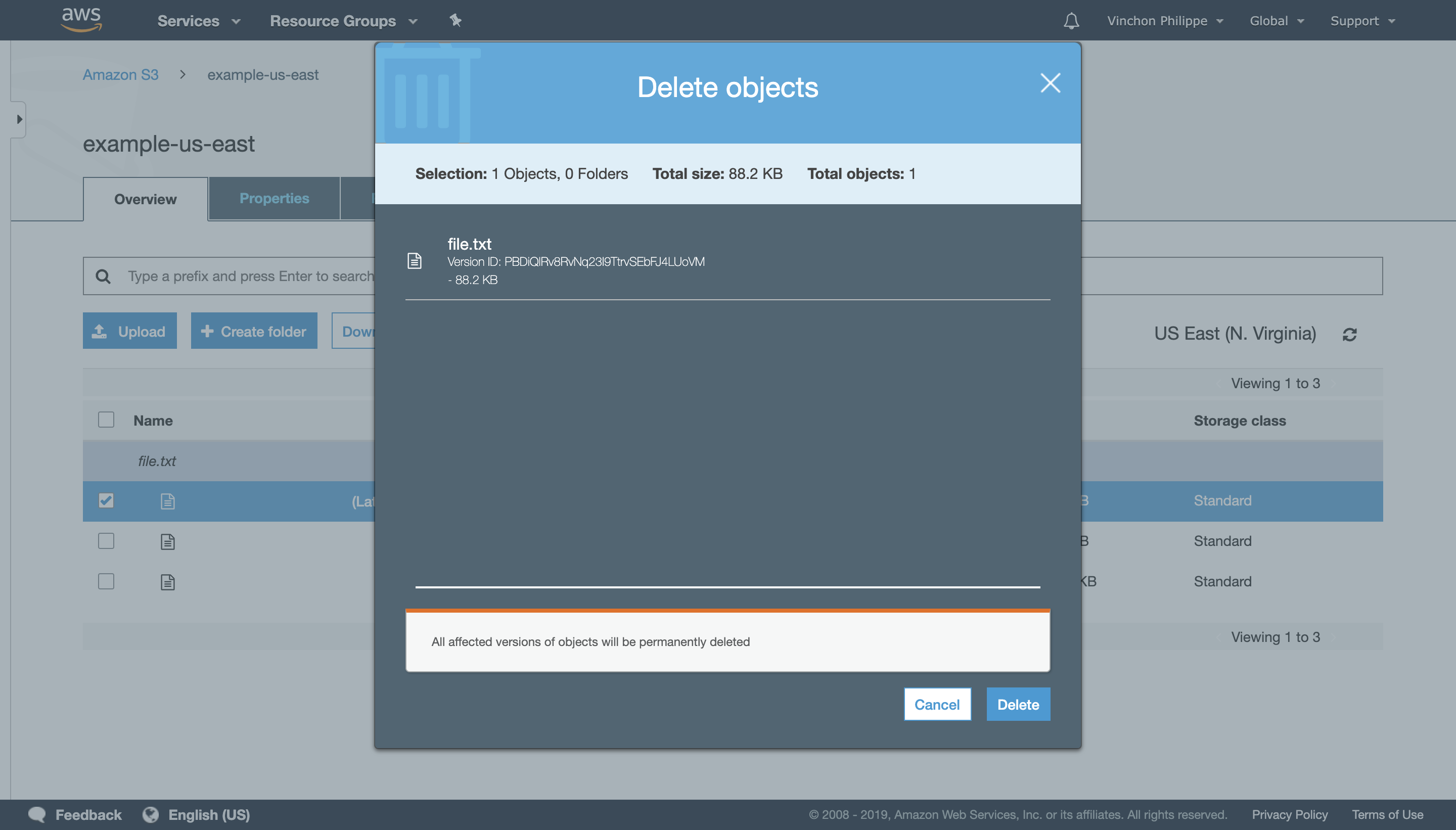
Once the bad version is removed, consumers should start retrieving the good one instead.
This useful functionality doesn’t come cheap.
Limiting costs
Storing every single version can be expensive. AWS will charge you for every Gigabyte used. This includes objects that are flagged as deleted. To avoid the ever-growing bill, old versions should be deleted or moved to a service like Amazon S3 Glacier.
This can be automated with Amazon S3 Lifecycle. Objects older than a given set of days can be automatically handled, but if you wish to keep more than the latest version some work is required.
A simple solution is to trigger an AWS Lambda when a new version is added. The function would delete, if needs be, older versions.
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
const AMOUNT_TO_KEEP = 3;
exports.handler = async (event) => {
const bucket = event.Records[0].s3.bucket.name;
const key = event.Records[0].s3.object.key;
const listParams = { Bucket: bucket, Prefix: key };
const listResponse = await s3.listObjectVersions(listParams)
.promise();
const deleteParams = {
Bucket: bucket,
Delete: {
Objects: listResponse.Versions
.splice(AMOUNT_TO_KEEP)
.map(v => ({ Key: key, VersionId: v.VersionId }))
}
}
await s3.deleteObjects(deleteParams).promise();
};
While this is a simple solution, it would still be expensive. The AWS Lambda would execute a LIST and DELETE operation for every PUT. While deletes are free, listing the content of a bucket is one of the most expensive requests.
To limit how often the LIST command is executed, the AWS Lambda should be triggered periodically with an Amazon CloudWatch Event. The frequency depends on how often files are pushed.
The AWS Lambda should retrieve all versions in as few calls as possible. Reducing the amount is important to keep the Amazon S3 bill low.
const listObjectVersions =
async(s3, bucket, prefix, keyMarker, versionIdMarker) => {
const params = {
Bucket: bucket,
Prefix: prefix,
MaxKeys: 1000,
KeyMarker: keyMarker,
VersionIdMarker: versionIdMarker
};
const response = await s3.listObjectVersions(params).promise();
const more = (!response.IsTruncated)
? []
: await listObjectVersions(
s3,
bucket,
prefix,
response.NextKeyMarker,
response.NextVersionIdMarker
);
return response.Versions.concat(more);
};
With all versions available, the deprecated ones should be extracted. The example bellow keeps only the most recent ones, but more logic could be included.
const groupVersionsByKeys = (versions) =>
versions.reduce((accumulator, v) => {
accumulator[v.Key] = accumulator[v.Key] || [];
accumulator[v.Key].push(v);
return accumulator;
}, {});
const extractVersionsToDelete = (versions, amountToKeep) =>
versions
.sort((a, b) => b.LastModified - a.LastModified)
.splice(amountToKeep);
The extracted versions can then be deleted.
const deleteObjectVersions = async(s3, bucket, versions) => {
if (versions.length === 0) return;
else {
const first = versions.slice(0, AWS_S3_MAX_KEYS);
const more = versions.slice(AWS_S3_MAX_KEYS);
const params = {
Bucket: bucket,
Delete: {
Objects: first.map(v => ({
Key: v.key,
VersionId: v.VersionId
}))
}
};
await s3.deleteObjects(params).promise();
await deleteObjectVersions(s3, bucket, more);
}
};
The AWS Lambda’s handler combines the functions defined above.
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
const BUCKET = 'example-us-east-1';
const AMOUNT_TO_KEEP = 3;
exports.handler = async(event) => {
const versions = await listObjectVersions(s3, BUCKET, '');
const byKeys = groupVersionsByKeys(versions);
const toDelete = Object.keys(versionsByKeys)
.map(k => extractVersionsToDelete(byKeys[k], AMOUNT_TO_KEEP))
.flat();
await deleteObjectVersions(s3, BUCKET, toDelete);
};
With everything in place, all but the last 3 uploaded versions of a Key will be deleted from the example-us-east-1 Bucket.
Amazon S3 is a great solution to many problems. The built-in versioning offers a simple revert mechanism, but at a price. If the built-in lifecycle management doesn’t work for you, the snippets above should help you keep the bill affordable.