Last month, I covered how to use AWS CodeBuild as a continuous integration solution. It finished with a simple example of continuous deployment. AWS supposedly has a better solution, AWS CodePipeline. Let’s see if this is true.
AWS CodePipeline has many similarities to AWS Codebuild. The biggest difference is how to structure the logic. AWS CodeBuild centralizes it. While AWS CodePipeline spreads it across many single-purpose components called actions.
These actions can be seen as functions. They have inputs, outputs, and are composable with one another. Most are specific, like pulling files from AWS S3 or deploying applications to AWS ECS. These only need some basic configuration to work. The remaining ones are very generic, running on AWS Lambda, or AWS CodeBuild. If this is still too limiting, custom actions can be created.

AWS CodePipeline group actions in stages. This simplifies flow reasoning by clustering actions logically. For example, actions are separated based on their environment. The grouping also affects the pipeline’s execution.
While many pipeline executions can coexist, a stage is limited to a single execution at a time. This allows actions to depend on previously ran ones of the same stage. It can guarantee that the build, the deployment, and the tests all use the same revision.
Before moving forward, there are important details that must be highlighted:
- Executions aren’t triggered by webhooks. They happen after identifying differences between the current state and the previous one. This can cause delays, but also a set of changes can trigger a single execution.
- Git sources, like AWS CodeCommit, and GitHub, can only watch a single branch. Pull requests won’t trigger executions.
- Git sources discard git information, making it unavailable to other actions. To circumvent those limitations, AWS CodeBuild will first integrate the code. At the end of the build specification, on the master branch, the repository will be zipped and pushed to AWS S3.
version: 0.2
phases:
build:
commands:
— echo Testing
- # run my test
- |
if [ $(git rev-parse — abbrev-ref HEAD) == ‘master’ ]; then
MY_ARTIFACT=/tmp/$(date "+%Y%m%d%H%M%S").zip
echo Push to AWS S3 to trigger AWS CodePipeline
zip -r . $MY_ARTIFACT
aws s3 cp $MY_ARTIFACT s3://my_bucket/my_key.zip
fi
The AWS CodePipeline’s first action monitors the AWS S3 file. The next action uses AWS CodeBuild. It builds a docker image, pushes it to AWS ECR, and creates a configuration file for AWS ECS. Other deployment services would require other actions, but similar logic.
version: 0.2
env:
variables:
ECR_REPOSITORY_URI: "my_ecr_repository"
ECS_TASK_CONTAINER: "my_ecs_tast_container"
phases:
build:
commands:
- VERSION=$(date "+%Y%m%d%H%M%S")
- echo Build docker image
- docker build -t $ECR_REPOSITORY_URI:$VERSION .
- echo Push docker image
- $(aws ecr get-login --no-include-email)
- docker push $ECR_REPOSITORY_URI:$VERSION
- echo Create task file
- |
printf \
'[{"name":"%s","imageUri":"%s"}]' \
$ECS_TASK_CONTAINER \
$ECR_REPOSITORY_URI:$VERSION > \
imagedefinitions.json
artifacts:
files: imagedefinitions.json
With the imagedefinitions.json file, the AWS ECS action only requires configuration. To avoid deploying straight to production, other stages can be added before. These would deploy the application to more private environments. The execution would continue only after manual approval.
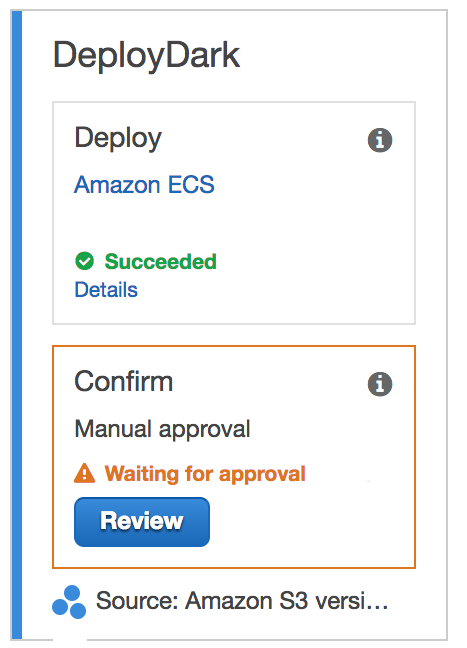
AWS CodePipeline isn’t a perfect product. It does offer a good continuous deployment solution but lacks continuous integration. This makes AWS CodePipeline another tool instead of a full replacement.
If deploying your master branch straight to production makes you uneasy, AWS CodePipeline could be for you. Just remember to add continuous integration.